 Video (EN)
Video (EN)
We present ActiveUMI, a framework for a data collection system that transfers in-the-wild human demonstrations to robots capable of complex bimanual manipulation. ActiveUMI couples a portable VR teleoperation kit with sensorized controllers that mirror the robot's end-effectors, bridging human-robot kinematics via precise pose alignment. To ensure mobility and data quality, we introduce several key techniques, including immersive 3D model rendering, a self-contained wearable computer, and efficient calibration methods. ActiveUMI's defining feature is its capture of active, egocentric perception. By recording an operator's deliberate head movements via a head-mounted display, our system learns the crucial link between visual attention and manipulation. We evaluate ActiveUMI on six challenging bimanual tasks. Policies trained exclusively on ActiveUMI data achieve an average success rate of 70\% on in-distribution tasks and demonstrate strong generalization, retaining a 56\% success rate when tested on novel objects and in new environments. Our results demonstrate that portable data collection systems, when coupled with learned active perception, provide an effective and scalable pathway toward creating generalizable and highly capable real-world robot policies.
The design of ActiveUMI facilitates an intuitive and efficient process for high-quality data collection while extending the operational boundaries from constrained laboratory settings to diverse, ''in-the-wild" environments. To this end, we have developed a low-cost, high-precision hardware system based on consumer-grade VR equipment, with its overall architecture depicted in Figure.

Overview of ActiveUMI collection. The left side of the figure illustrates our data collection process and the detailed dataset configuration. The training data from in-the-wild data collected by ActiveUMI. The right side of the figure shows the model deployment and inference process.
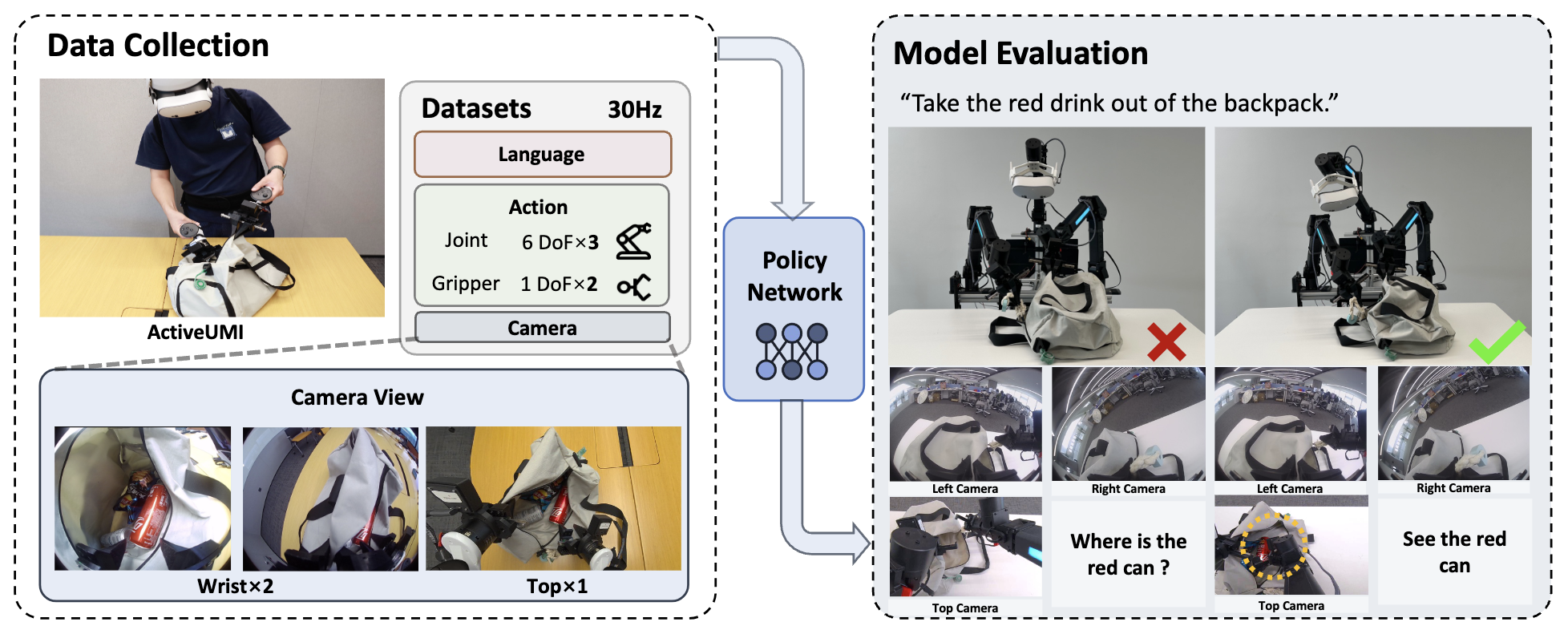
ActiveUMI is designed for data collection in the wild, which improves the generalization of robotic autonomous execution. We demonstrate both the process of ActiveUMI collecting data in the wild and the performance of robots when deployed in previously unseen environments.
ActiveUMI captures the operator's head movements during teleoperation, enabling the robot to learn active perception strategies. This allows the robot to dynamically adjust its visual attention during task execution, similar to how humans naturally move their heads to gather relevant visual information.
We evaluated our approach on a diverse set of tasks, each requiring a different skill set: Block disassembly is a precision task where the robot must separate two small, interlocked blocks and then sort them into a box. Shirt folding is a deformable object manipulation task that demands accurate state recognition to correctly fold the cloth. Rope boxing is a long-horizon task where the robot must neatly place a long rope into a box. Toolbox cleaning is an articulated object manipulation task that requires the robot to close the lid. Bottle placing is a task designed to test the policy's robustness to large positional variations of the objects.

Data Collection Comparison. (a)-(d) We utilize efficiency comparison among ActivateUMI, bare hand, and teleoperation in two tasks: rope boxing and shirt folding. ActivateUMI reaches an efficiency level between bare hand and teleoperation, and consistently outperforms teleoperation across both tasks. (e) The comparison of relative pose error between UMI and ActiveUMI.

In conclusion, we identified a critical limitation in current robot data collection methods: the neglect of active, egocentric perception. While humans naturally move their heads to understand and interact with the world, most robot learning systems rely on action-centric, wrist-mounted cameras that limit performance on complex, long-horizon, or occluded tasks. To address this, we introduced ActiveUMI, a portable, in-the-wild data collection framework that couples high-fidelity embodiment alignment with learned viewpoint control. Our experiments demonstrate that this approach is highly effective. Policies trained exclusively on ActiveUMI data achieve a 70% success rate on a variety of challenging bimanual tasks. Crucially, our method significantly outperforms baselines that lack active perception, confirming that learning how to look is as important as learning what to do. The strong generalization performance on novel objects and scenes further validates the quality of in-the-wild data collected with this approach.
@misc{zeng2025activeumiroboticmanipulationactive,
title={ActiveUMI: Robotic Manipulation with Active Perception from Robot-Free Human Demonstrations},
author={Qiyuan Zeng and Chengmeng Li and Jude St. John and Zhongyi Zhou and Junjie Wen and Guorui Feng and Yichen Zhu and Yi Xu},
year={2025},
eprint={2510.01607},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2510.01607},
}